単語の分散表現の性能評価に用いる上で、JWSAN-2145 には以下の2つの問題があります。
- JWSAN-2145に含まれる単語(形態素)のうち、一般に用いられる形態素解析器の辞書に掲載されていない 単語が存在する。
- JWSAN-2145に含まれる単語ペアの類似度や関連度の分布が偏っている。
問題 1 については、本データセットを作成するに当たり、国立国語研究所の規定した言語単位(短単位)に基づく UniDic を用いて、対象の単語を選定しています。よって、mecab や juman などの多くの形態素解析器に用いられる形態素辞書には含まれない形態素が存在します。例えば、「心地良い」という単語は mecab(ver 0.996) +ipadic(ver 2.7.0) や juman(ver 7.0.1) では1形態素として切り出されません。(異なる表記の「心地よい」はいずれの形態素解析器でも1形態素として切り出せます。しかし、一般的に言って、評定値は表記の影響を受けるので、「心地良い」を「心地よい」で置き換えるのは心理学的に妥当ではありません。)
問題 2 については、以下に JWSAN-2145 に含まれる 2145 ペアの類似度(Similarity)と関連度(Association)の分布を示します。
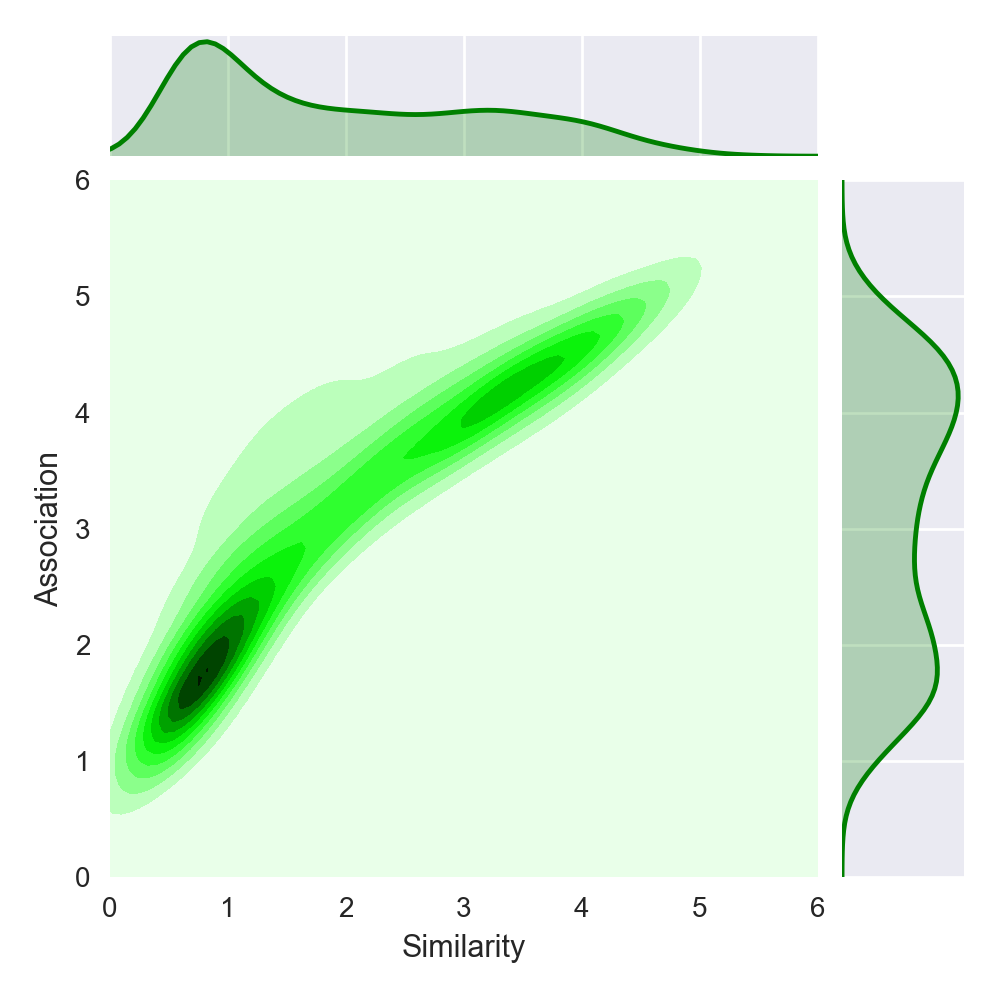
この図を見ると、類似度・関連度ともに低い値に偏っているとともに、 類似度と関連度の両方とも低いペアが多い(図の左下の部分の色が濃い)ことがわかります。 一般的に言って、類似度、関連度ともに低い単語ペアは、どのような分散表現を用いても コサイン類似度が低くなる傾向にあります。 このような「簡単な」単語ペアが多く存在すると、 相関係数が実際の分散表現の性能以上に高くなってしまうという恐れがあります。
実際に、現代日本語書き言葉均衡コーパス(BCCWJ)から skip-gram(5ウインドウ,300次元)+ negative sampling(サンプル数5)で学習した単語分散表現を用いて、JWSAN-2145 の単語ペアに対するコサイン類似度を算出し、JWSAN-2145の類似度および関連度との順位相関を取ると、以下のようになります。
関連度: 0.75 (n=2145)
一般的に、英語の分散表現では、関連度(WordSim-353など)との相関に比べて、 類似度(SimLex-999)との相関は かなり低くなります。 例えば、Levy et al.(2015)では WordSim との相関は 0.79 くらいに達しますが、SimLex との相関は良くても 0.44 程度です。 このことは、単語の分散表現で(関連度ではなく)類似度を予測することの難しさを示しています。 しかし、上記の相関分析の結果では、類似度と関連度の相関に大きな差は見られません。 よって、類似度・関連度分布の偏りが単語分散表現の適切な性能評価を妨げている可能性を否定できません。
以上のような問題点をできるだけ回避して、日本語単語の分散表現の性能を適切に評価でき、かつ評価用データとして広く利用してもらうために、以下の方法で 1400 ペアを選定したのが JWSAN-1400 です。
- mecab(0.996)+ipadic(2.7.0) もしくは juman(7.0.1) に含まれない形態素 (異なる表記で登録されている形態素も含む)含む単語ペアを除外する。
- 類似度と関連度の評定値の低い単語ペアに対して、 出現頻度の低いものを除外する。
JWSAN-1400 における類似度と関連度の分布は以下のようになります。
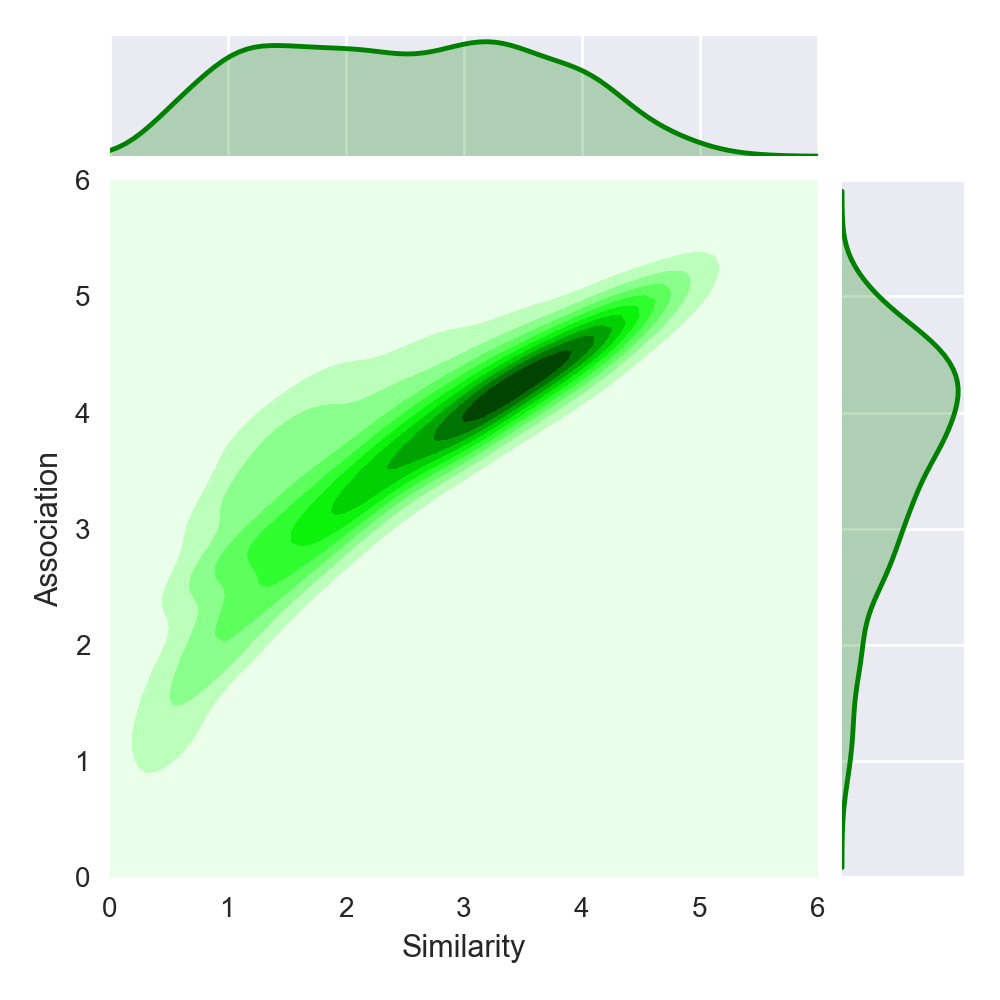
また、JWSAN-1400 を用いて、前述の単語分散表現の評価結果(順位相関係数)は以下のようになります。
関連度: 0.64 (n=1400)
よって、JWSAN-1400 では、上述した2つの問題が(完全ではないかもしれないが)おおよそ 解消されていると言えます。